on
Lecture 1: Introduction to Reinforcement Learning
Overview
Contents
“Reinforcement learning is learning what to do—how to map situations to actions—so as to maximize a numerical reward signal”
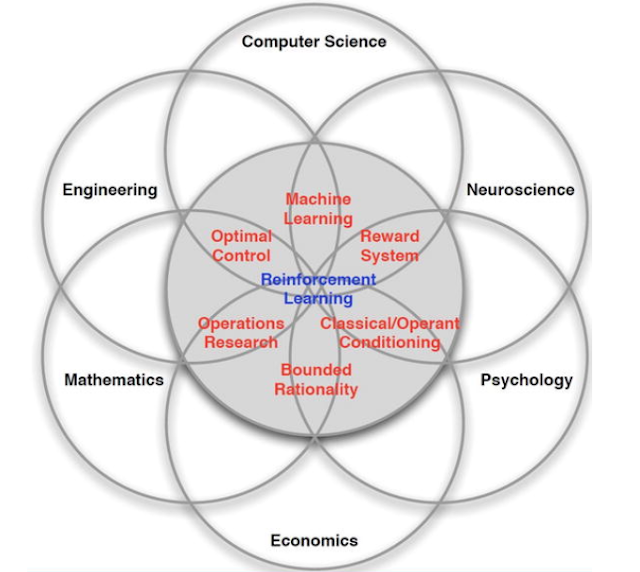 RL에 필요한 여러 다른분야의 이야기가 많이 있는데 기본적으로 모든부분이 decision making을 어떻게 효과적으로 하는가에 대한 이야기이다. 좋은 의사결정은 상을 받고 그렇지 않다면 벌을 받는다
RL에 필요한 여러 다른분야의 이야기가 많이 있는데 기본적으로 모든부분이 decision making을 어떻게 효과적으로 하는가에 대한 이야기이다. 좋은 의사결정은 상을 받고 그렇지 않다면 벌을 받는다
머신러닝은 크게 다음과 같은 3가지 카테고리로 분류가능
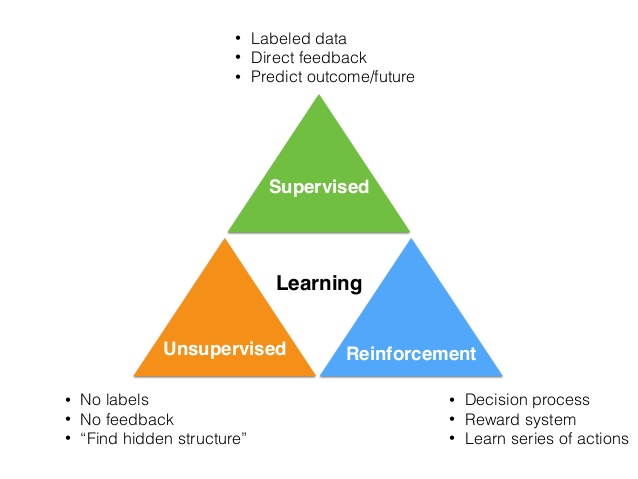
강화학습은 학습을 하는 “방식”으로 구분되는 것이 아니고 강화학습 “문제”인가로 구분된다.
강화학습의 특징은 다음과 같다
- supervisor 가 없다 (어떤게 최선인지 알려주지 않는다. 오로지 Trial and error를 통해)
- feed back이 delay되어 들어옴
- 시퀀셜한 데이터가 들어옴(not i.i.d data -> 각 데이터가 correlation 되어 있음)
- agent의 action에 따라 input data에 영향이 생긴다
architecture
전체 구조는 다음과 같다. 여기서 목적은 뇌 그림쪽에 있는 agent를 어떤식으로 만들것인가다.

- 뇌: agent
-
지구: environment
- At each step t the agent:
- Executes action
- Receives observation
- Receives scalar reward
- The environment:
- Receives action
- Emits observation
- Emits scalar reward
- t increments at env. step
agent입장에 action만이 environment 에 영향을 미치는 채널이다. agent에 input, output되는 모든것들이history, experience를 형성
전체 스토리를 상기하자. 시작은 RL의 Goal 부터
- RL의 Goal은 미래의 예상되는 Reward합을 최대화 시키는 것. 최대화 할 수 있는 path를 따라야한다
- agent는 그 path를 시작하는 action을 pick해야한다
- agent에서 action을 pick하기 위해서는 state필요
- 미래의 action을 pick해야 하니까 미래의 state를 예측해야 한다. observation에 따라 다음 두가지 경우
- Fully Observable: 은 (history)를 MDP에 넣어 생성
- Partial Observable: Beliefs또는 rnn 통해 생성
Reward
Reinforcement learning is based on the reward hypothesis. RL은 이 reward를 최대로 쌓는 쪽으로 움직인다.
Reward의 특징은 다음과 같다
- A reward Rt is a scalar feedback signal
- Indicates how well agent is doing at step t
- The agent’s job is to maximise cumulative reward
single scalar feedback은 효과적. 의사결정 시 여러 goal 중 어떤것을 따를 것인가를 보는데, 이것은 RL관점에서는 어떤 action을 pick 할 것이냐라는 말. 해서 같은 축(thresh hold 같은)에 놓고 비교를 해야하는데 이때 scalar가 효과적
Sequential Decision Making 이야기로 가면
- Goal: select actions to maximise total future reward
- Actions may have long term consequences
- Reward may be delayed
- It may be better to sacrifice immediate reward to gain more long-term reward
History and State
The history is the sequence of observations, actions, rewards
여기서 state가 사용되는게 아니고 ot가 사용되는 이유는 agent는 env중에 관측가능한 부분만 받아들일 수 있기때문. 히스토리는 experience of the agent. 이는 RL에서 사용되는 데이터다(stream of data)
What happens next depends on the history:
- The agent selects actions
- The environment selects observations/rewards
State is the information used to determine what happens next. 다음에 뭐가 일어날지 결정하는데 사용할 정보(history)의 summary. State는 설정하기 나름 영상이라고 해서 반드시 현재의 1프레임일 필요없다. deep q net 논문에서는 Atari game에 4프레임을 합쳐서 사용
Formally, state is a function of the history:
보통은 valid definition state 는 last 샘플만, 그전꺼는 무시 (MDP). 일반적으로 RL에서 state라고하면 agent state를 이야기함
Information State는 state를 수학적으로 표현하는 방법. Markov state라고 한다.
위 수식을 만족할때 Markov 하다고 함. 다음 스테이트를 생성할때 현재의 스테이트를 통해 생성될 확률과 현재에서부터 모든 과거를 포함한 스테이트들을 통해 생성되는 확률이 같을때. 조금더 풀어쓰면 다음과 같다.
위에서 기술했듯이 현재상태는 히스토리에 펑션을 돌려서 나온 결과, 이를 통해 미래 모든 히스토리를 예측가능. 미래의 모든 히스토리에는 미래의 모든 리워드들도 포함되어 있기때문에 리워드들을 예측가능함.
Environment state는 Markov 하다. 또한 history는 Markov 하다
1. Environment State
진짜 환경의 상태. action을 인풋으로 받고 현재의 환경의 상태를 스까서 다음 observation, reward를 생성. agent에서 전체가 안보일 수 있음. agent에서 관측가능하더라도 사용못할 정보들이 있을 수 있음
2. Agent State
에이전트 내부에서 관리하는 상태. observation을 갖고 만P든다 에이전트 스테이트는 알고리즘안에 현재 환경이 어떤지(observation)를 summarize하고 다음 액션을 픽하는데 사용. observation에서 어떤 정보를 취득하고 버릴것인가. pick action!!!!
It can be any function of history
observation
환경에서 일어나는 일들을 관측.
1. Fully Observable Environments
Full observability: agent directly observes environment state
environment는 markov 하므로 agent state또한 markov하다. 따라서 다음 스테이트는 MDP로 생성
문제사이즈가 매우 작거나, 말도안되는 연산능력과 저장용량이 있거나 일때 가능할듯
2. Partially Observable Environments
Partial observability: agent indirectly observes environment
보통 일반적인 상황. 환경의 일부만을 관측한다. 다음 스테이트는 partially observable Markov decision process (POMDP)로
Beliefs 해당 status가 일어날 확률로 표현. 이 벡터들을 전부 더해서 스테이트로 쓴다.
RNN 스테이트를 리니어하게 표현
Major Components of an RL Agent

- policy: 다음 액션을 어떻게 pick 할 것인가. agent의 행동양식
- value function: 특정 state나 특정 action에 가치를 부여. action value function은 q value func라고함
- model: agent가 env를 보는 view.
1. Policy

- policy is the agent’s behaviour
- It is a map from state to action, e.g.
- Deterministic policy: a =
- Stochastic policy:
2. Value function

- Value function is a prediction of future reward
- Used to evaluate the goodness/badness of states
- And therefore to select between actions, e.g.
- : discount 비율
3. Model

Categorizing RL agents

- Value Based
- No Policy (Implicit)
- Value Function
- Policy Based
- Policy
- No Value Function
- Actor Critic
- Policy
- Value Function
- Model Free
- Policy and/or Value Function
- No Model
- Model Based
- Policy and/or Value Function
- Model
Exploration and Exploitation
- Exploration nds more information about the environment
- Exploitation exploits known information to maximise reward
- It is usually important to explore as well as exploit
video
13p single scalar feedback은 효과적. 여러 복잡한 goal 중 어떤것을 따를 것인가, optimizing 할것인가. RL 관점에서는 pick action이 goal로 가는 방법. 그 goal들을 비교하기 위해 같은 축(thresh hold 같은)에 놓고 비교를 해야하는데 이때 scalar가 효과적
16p 우리는 이 뇌 안쪽에 알고리즘, agent 를 만드는게 목표다
17p env는 obs 와 reward를 gen한다. env는 어쩔수 없다. action만이 env에 영향을 미치는 채널이다. that time series defines the experience of the agent experience는 RL에서 사용되는 데이터다(stream of data)
18p State 중요한 개념. summary 다음에 뭐가 일어날지 결정하는데 사용할 정보. valid definition state 는 last 샘플만, 그전꺼는 무시
19p 질문 멀티 에이전트에서는 어케? 다른 에이전트들은 그냥 환경으로 생각. 에이전트 브레인에서 환경속 브레인으로 전달가능? 가능하나 …
20p 에이전트 스테이트는 알고리즘안에 현재 환경이 어떤지(obs)를 summarize하고 다음 액션을 픽하는데 사용. our desicion은 observation에서 어떤 정보를 취득하고 버릴것인가. pick action!!!!
21p information stated은 Markov state라고도 불리며 기본적으로 information 이론적인 컨셉이다 이것은 언제 state를 만드는 것이 hitory 의 유용한 정보들을 모두 포함할 것인가를 설명 미래의 h를 예측하기위해 모든 과거의 h가 필요없음. 단시 현재의 s만이 필요 S_t는 미래의 모든 history생성하는데 사용됨. history는 r을 포함하니까 미래의 모든 r을 구할 수 있다. 마르코프는 과거는 필요없음 미래를 예측하는데 현재의 상태만이 필요하다. 질문 헬기 이야기. 스테이트는 각도 위치 속도 각속도 등등, 10분전 상태 같은 예전 궤도는 필요없다 non 마코프에서는 필요함 마코프에서 는 미래의 모든리워드 포함
p23 세개 모두 같은량, env stat이 agent stat으로 사용됨. best case. state를 표현하는 form MDP. 모두 환경요소를 관측이 불가능하기때문에 MDP를 이용해서 실제적인 문제를 이해
p24 파샬관측. 방안로봇은 카메라를 통해 방안만을 본다. 트레이딩 에이전트. 현재 가격만 본다. 어디서 왔는지 모름 카드. 테이블에 까진것만 안다. 숨겨진거 모름 Beliefs 해당 env stat이 일어날 확률로 표현. 이 벡터들을 전부 더해서 스테이트로 쓴다 RNN 스테이트를 리니어하게 표현
p25 policy: 다음 액션을 어떻게 pick 할 것인가 value: state와 action에 가치를 부여 modle: agent가 env를 보는 view
p26 deterministic: 매핑함. 경험을 통해 배움. 리워드를
p31 리스크: ???
p33 transition: 헬기가 이런 각도와 이런 방향 이런 위치에 있을떄 바람이 불면 이렇게 뒤집는다. 어떤일이 다음스텝에 일어날지 이거를 배운다 Rewards: 액션 픽할떄 리워드 옵셔널 ??? 많은 코스에서 모델 프리 메서드에 주목한다
p33 에이전트가 위쪽 궤도를 따라갔다고 했을때 매 스텝마다 리워드가 -1 되는것을 나타낸다. 타임 지날때마다 -1이라고 써있음. 이해된 다이나믹 env를 나타냄
p34 value base: policy 안쓰고 리워드 좋은놈을 쫓아간다
p35 model free: 명확하게 환경을 이해하려고 하지 않음. 헬기 예제 헬기 움직임. 단순히 바로 exprience에 p , v model base: 환경이 어케변할지 모델 만ㄷ름
p37 reinforceme l: 환경안다. planning: 다르다 작업을 할 환경에 대한 모든것을 알려줌. 게임의 룰. 헬기라면 바람에대한 수식들같은… 실제 환경에서 수행하는게 아닌 완벽한 인터널 모델과 인터액션으로 계산을 수행 그렇게 policy를 업그레이드
p38 실제로 게임 하는것 RL
p39 에뮬레이터로. 오른쪽 그림과같이 액션에 따라서 반응하는 완벽한 환경이 갖춰져있음. 액션에따른 환경변화의 서브트리를 만들 수 있다.
p41 exploration은 리워드를 어느정도 포기하고 env에서 새로운것을 찾는다 exploitation은 리워드를 최대치로하는 쪽으로
p43 ??? Prediction: 현재의 policy를 따랐을때 agent가 할 행동이 얼마나 좋을까 control: policy를 최적화 RL에서는 이 2문제를 모두 풀어야함